Apstra Test Drive Guide
Aomalies In The Fabric & AIOps With Data Center Assurance
Exploring Fabric Health via Anomalies
Apstra monitors anomalies, which are deviations from your intended network design. When you build your fabric, you define exactly how the network should operate. Behind the scenes, Apstra creates a detailed model of all the relationships and dependencies across your infrastructure, giving it complete context of your network’s expected state. If your deployed fabric deviates from that intent in any way, Apstra raises an anomaly and allows you to investigate the issue.
Here we can see current anomalies in this network, ranging from missing routes and failed BGP peerings to incorrectly cabled interfaces. Each anomaly shows what the intent should be alongside the current state in red, clearly indicating where things aren’t right.
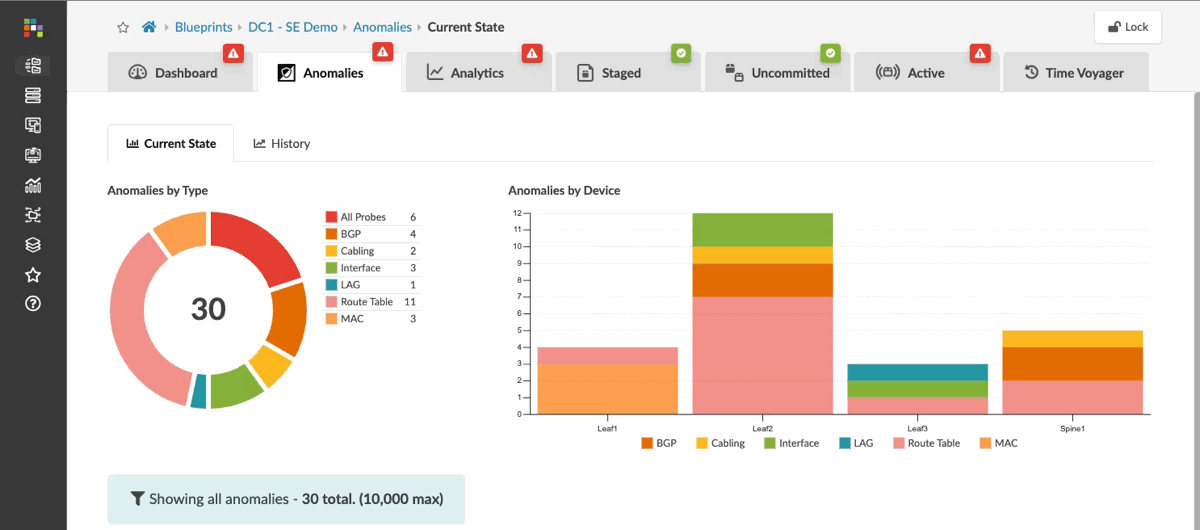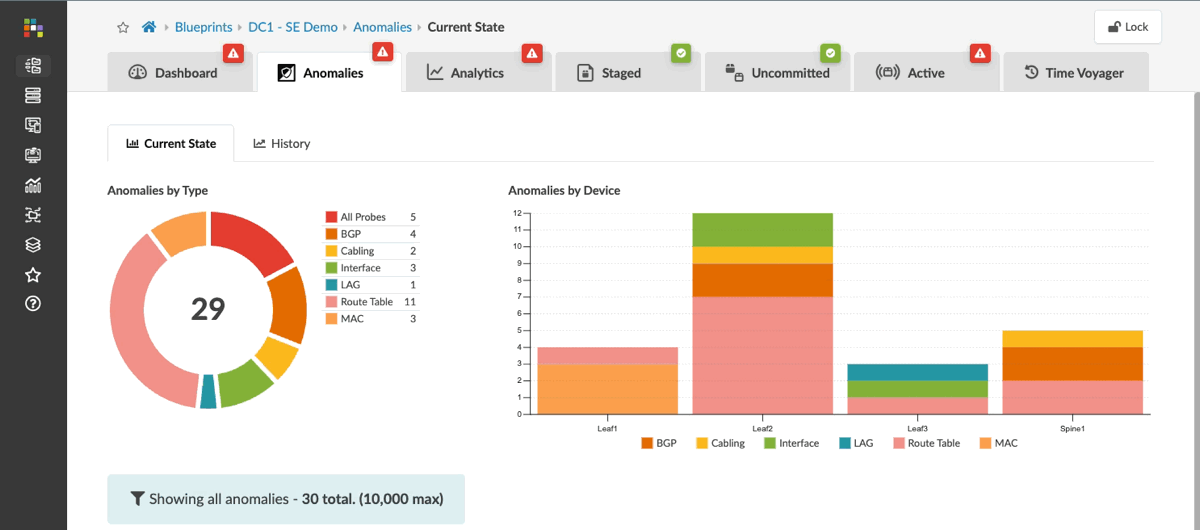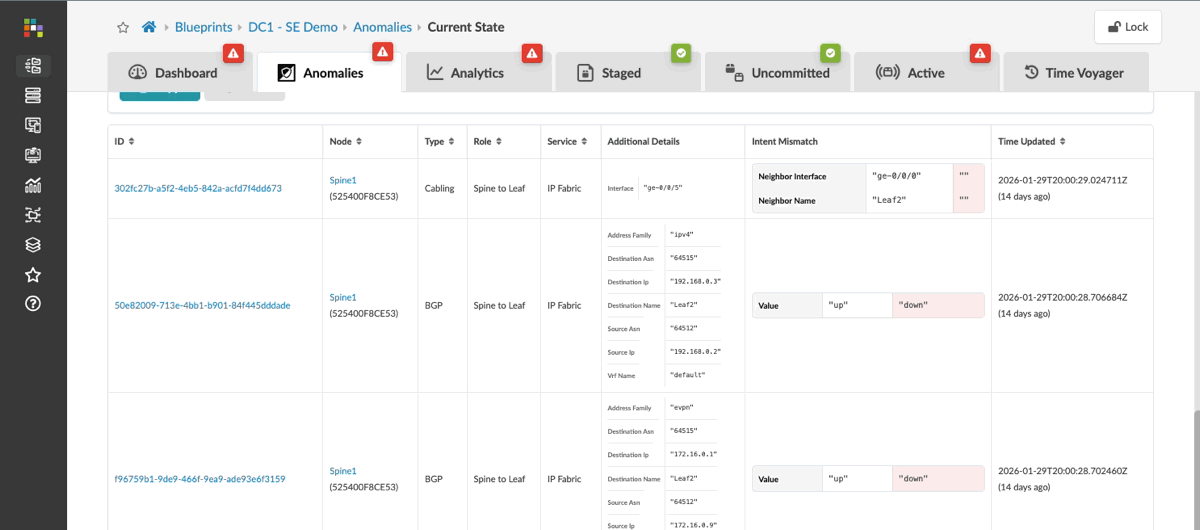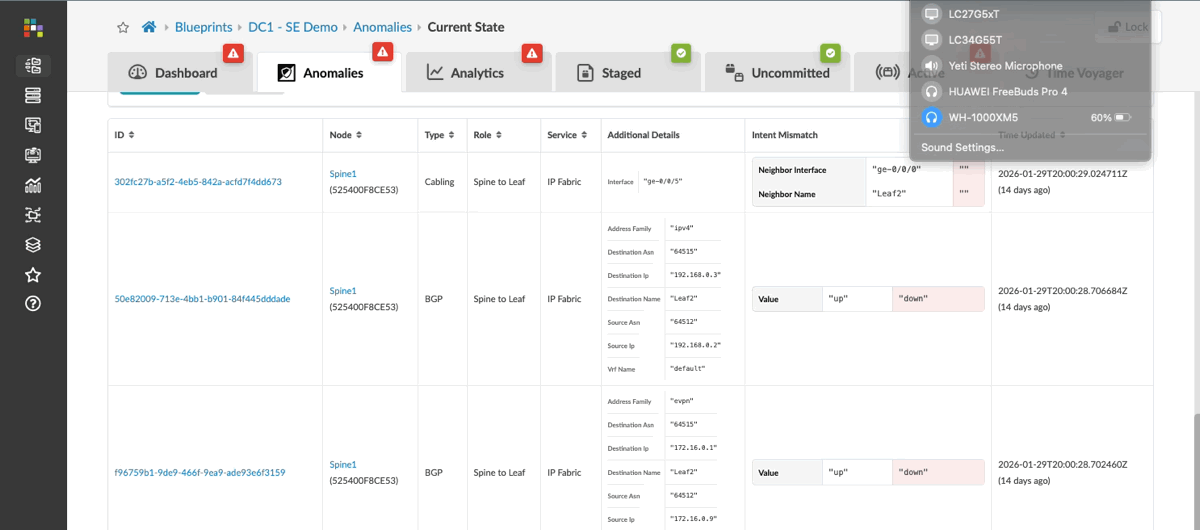
You can also review the past 30 days to see how your fabric has changed over time, including issues that have occurred and been resolved. This historical view helps you identify potential triggers for problems you’re currently observing on the fabric.
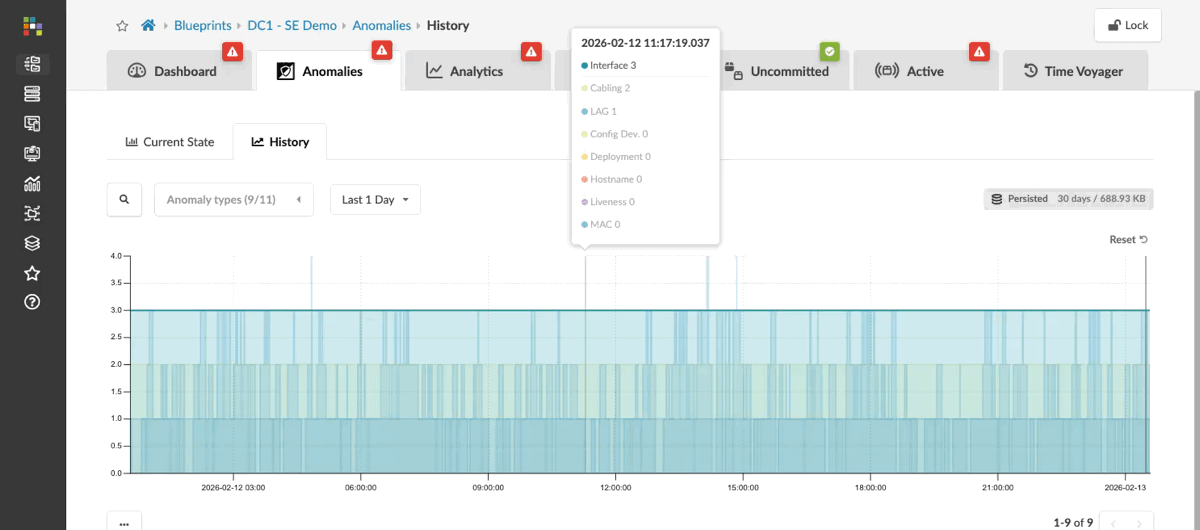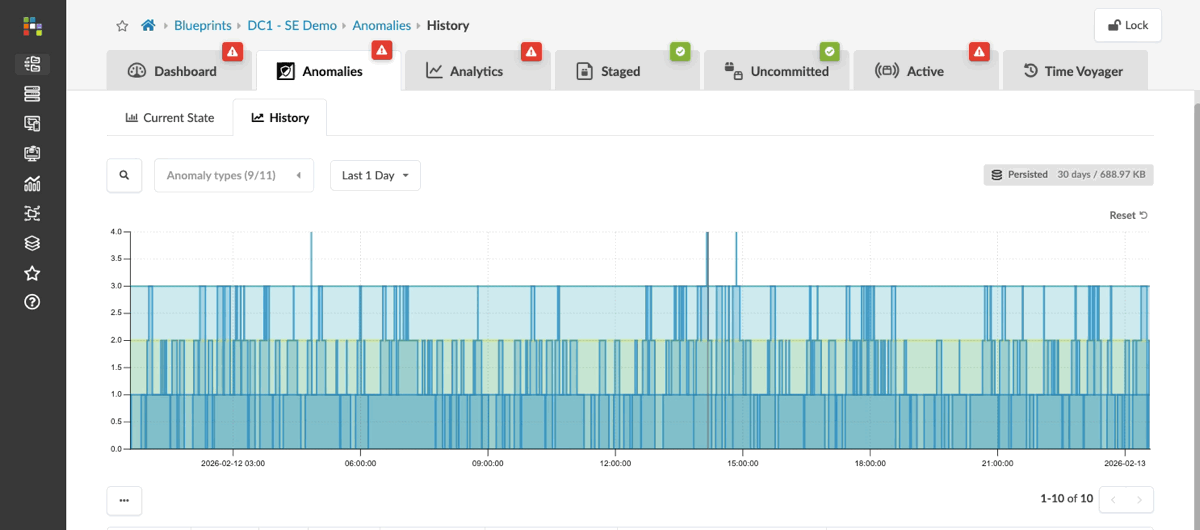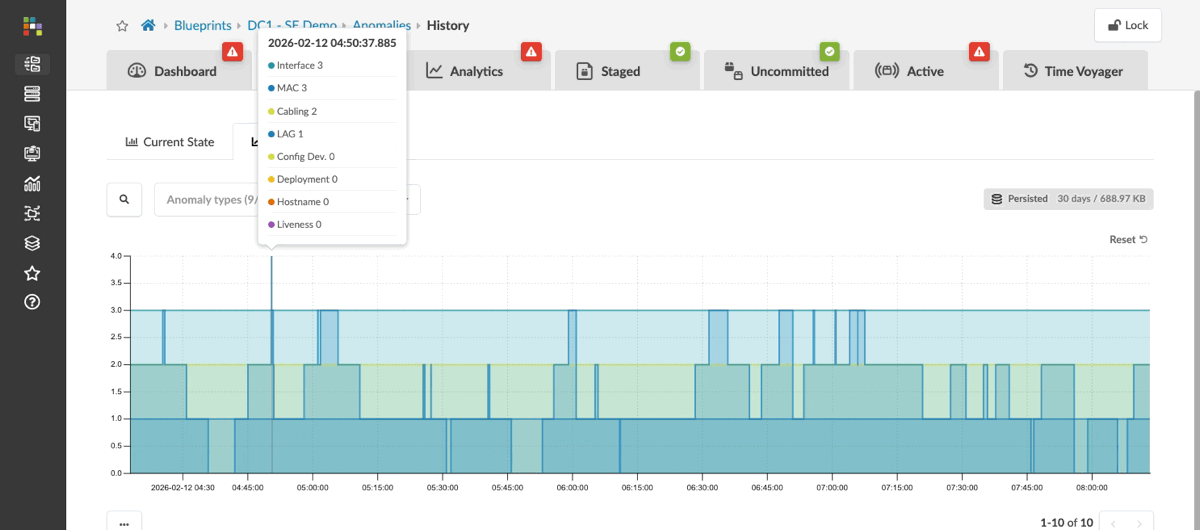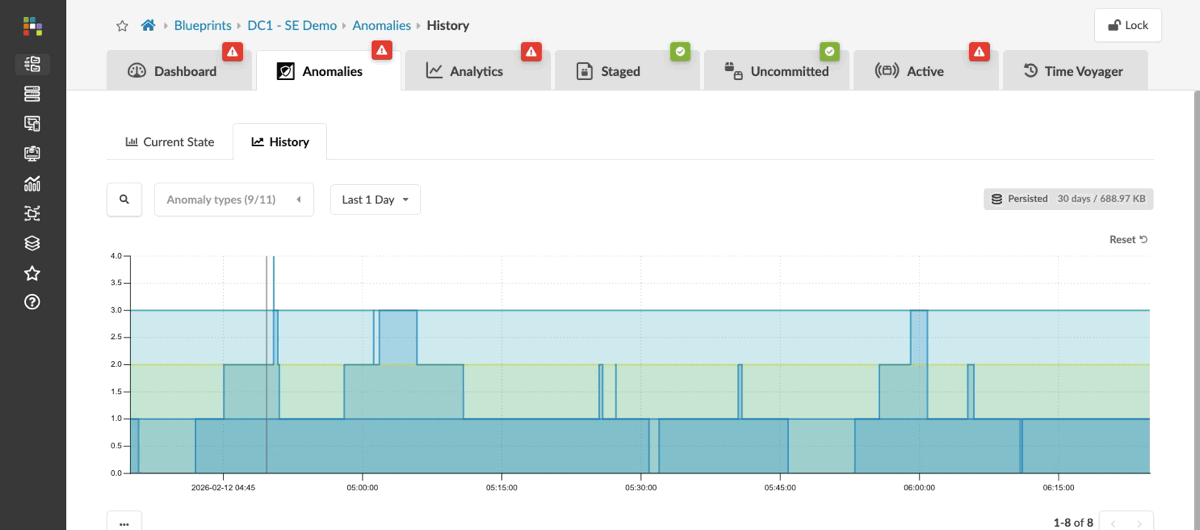
Now let’s see how we can connect these anomalies to what’s actually happening on the data centre fabric and understand the impact on clients trying to access the services they need.
Data Center Assurance
Data Centre Assurance is Juniper’s cloud-based AIOps platform that provides continuous monitoring and intelligent analysis of your data centre infrastructure. Rather than waiting for users to report problems or manually checking devices, it collects telemetry from your Apstra-managed fabrics and uses machine learning to identify anomalies, predict potential issues, and help you understand what’s happening across your network. The platform processes this operational data to surface insights about service health, connectivity problems, and performance trends that would otherwise remain hidden in logs and metrics.
The value of Data Centre Assurance lies in shifting from reactive troubleshooting to proactive operations. When something does go wrong, the platform helps you understand the scope of impact, which services are affected, what changed recently, and where to focus your attention first. It also provides visibility into longer-term trends, helping you spot patterns like gradually increasing memory utilisation or recurring connectivity issues before they become critical. This changes the operational model from "fix things when they break" to "prevent things from breaking in the first place", which is particularly valuable in environments where network stability directly impacts business services.
|
You can access to Data Center Assurance by signing up here - https://get-dca.osiodyssey.com/ You will recieve an email with instructions on how to sign up for an account. |
Here’s an overview of what you can see in Data Center Assurance
This video demonstrates how Data Centre Assurance maps services and clients across your network whilst highlighting issues in real time. Within a few clicks, you can identify the root cause of problems that would typically take considerably longer to diagnose manually. The actual fix is usually straightforward once you understand what’s happening – it’s the investigation and identification process that consumes most of your operational time and effort.
Sign up to our demo environment and check out exactly what you can see in DataCenter Assurance!
The Power of Intent-Driven Monitoring and AIOps
What makes Apstra’s monitoring truly powerful is its integration with your intent model. This means:
-
Automatic adaptation: As your network changes, monitoring adapts automatically
-
Relevant context: Anomalies are presented with full context of your design intent
-
Reduced noise: You only see alerts for true deviations from intent, not normal operations
-
Historical tracking: You can review how your fabric has changed over the past 30 days to identify patterns and triggers
When combined with Data Centre Assurance’s AIOps capabilities, you shift from reactive troubleshooting to proactive operations. The platform continuously analyses telemetry from your Apstra-managed fabrics, surfacing insights about service health and connectivity that would otherwise remain hidden in logs and metrics.
What You’ve Learned
You’ve now seen how Apstra’s monitoring and analytics capabilities provide:
-
Real-time anomaly detection that identifies deviations from your network intent
-
Historical analysis to track fabric changes and identify issue triggers over time
-
Integration with Data Centre Assurance for AI-driven service mapping and root cause identification
-
The ability to shift from "fix things when they break" to "prevent things from breaking in the first place"
This completes our exploration of Day 2 monitoring in Apstra, from expanding your network to monitoring its health and predicting potential issues. You’ve seen how Apstra transforms complex networking tasks into simple, intent-driven operations whilst providing the visibility needed to maintain service reliability.
Just one last thing to do before we wrap up this lab - let’s rollback your fabric!